Intel has shared new details about Texture Set Neural Compression, or TSNC, and the company now positions it as a practical solution instead of just a research demo, while moving the technology into a standalone SDK with a flexible decompression API that developers can compile using C, C++, or HLSL depending on their workflow.
Intel explained that TSNC uses neural networks to compress textures more efficiently than traditional methods, and the system supports both a fallback fused multiply-add path for CPU and GPU, along with a faster linear algebra path that uses XMX acceleration on supported Intel GPUs, which improves performance significantly during decoding.
How TSNC works
TSNC moves beyond standard block compression by training a neural network to encode and decode groups of textures together, and Intel stores compressed data in a four-layer BC1-based feature pyramid while reconstructing textures through a three-layer MLP decoder, which allows the system to balance storage savings and runtime performance.
Developers can use this system in different ways, including install-time decompression, load-time processing, streaming, or even per-pixel runtime sampling, depending on whether the goal is to reduce storage size, memory bandwidth, or VRAM usage.
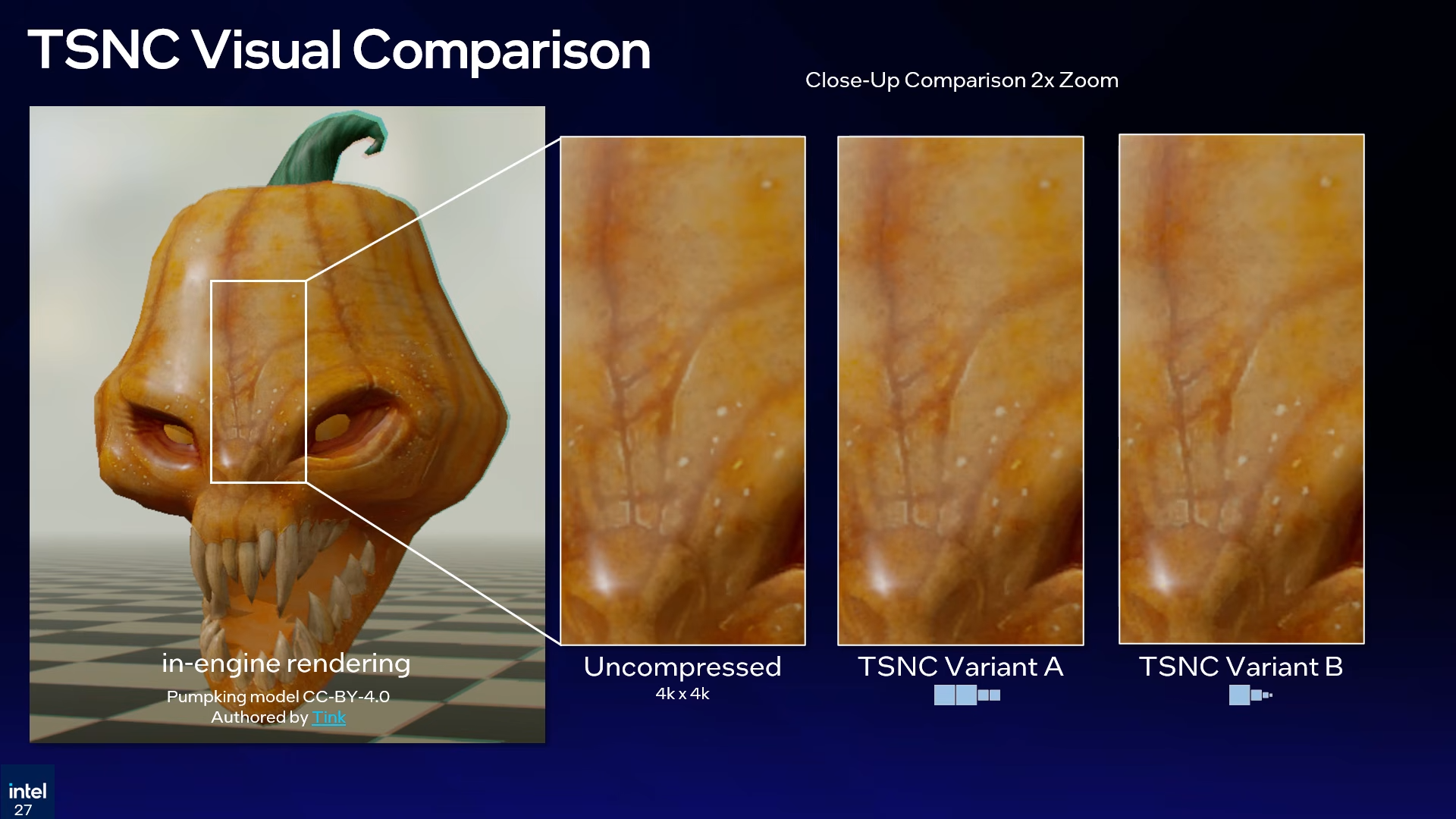
Compression gains and trade-offs
Intel compared TSNC against standard BC compression and showed clear improvements, where traditional methods reached around 4.8x compression while TSNC Variant A crossed 9x and Variant B pushed beyond 18x, delivering much higher space savings but with visible trade-offs in image quality.
Variant A keeps more visual detail but still shows slight precision loss in normals, while Variant B increases compression further and introduces more noticeable artifacts, especially in normals and ARM data, and Intel’s perceptual analysis estimates around 5 percent quality loss for Variant A and up to 7 percent for Variant B.
Intel also shared performance data from Panther Lake B390 graphics, where the fallback path averaged 0.661 nanoseconds per pixel while the XMX-accelerated path reached 0.194 nanoseconds per pixel, which results in roughly a 3.4x speed improvement during decoding.
The company plans to release an alpha version of the TSNC SDK later this year, followed by a beta phase and then a full public release, as Intel continues pushing neural compression as a core part of future graphics pipelines.


